Omics Data Analysis
I have designed software platforms and tools to process and analyze large sets of sequencing data in order to find similarities across diverse omics datasets and to build network models to interrogate databases against each other to help biological scientists to build hypothesis.
Currently, we are developing additional software tools to analyze spatial transcriptomics datasets and to infer spatial information of cellular systems.
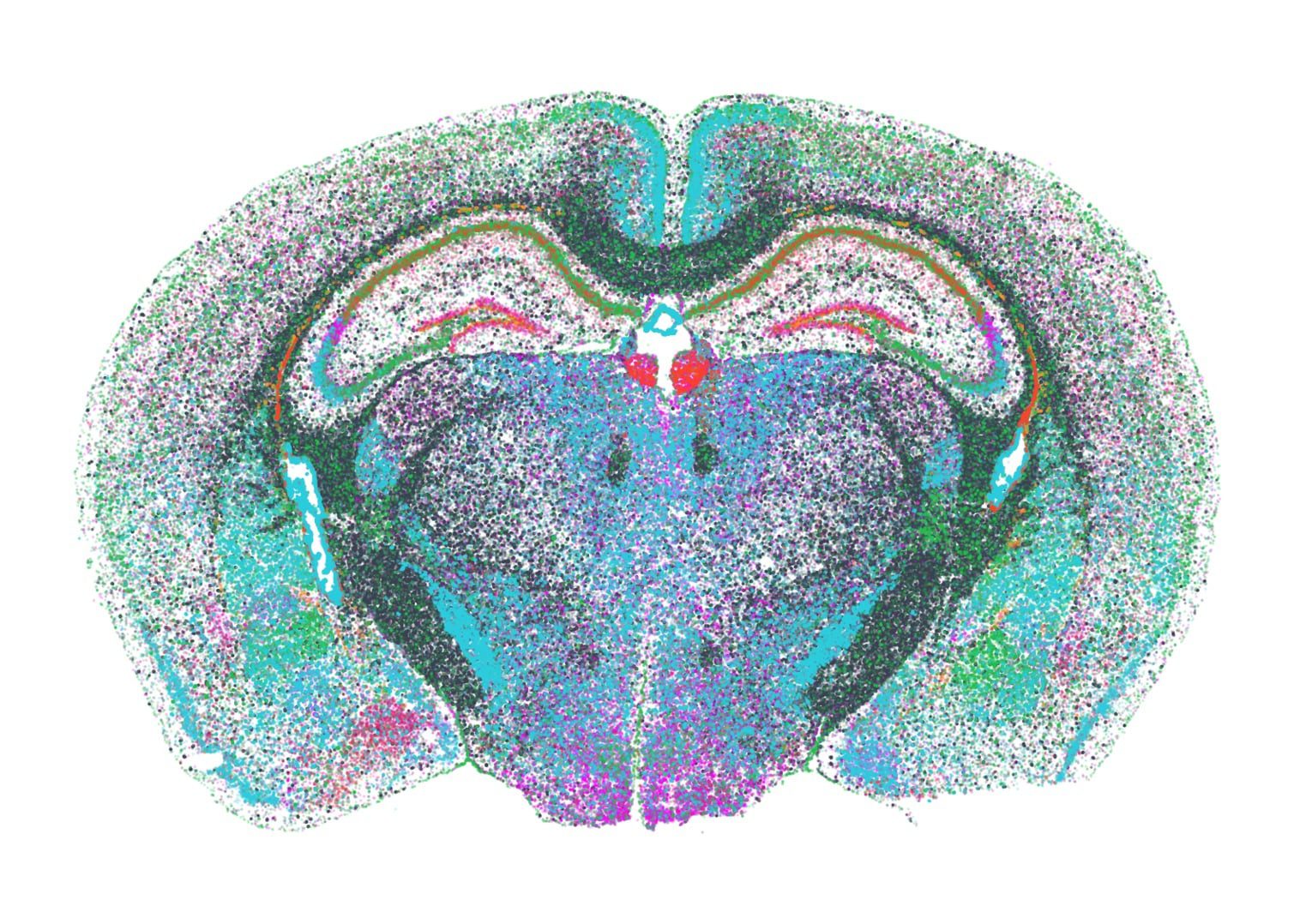
|
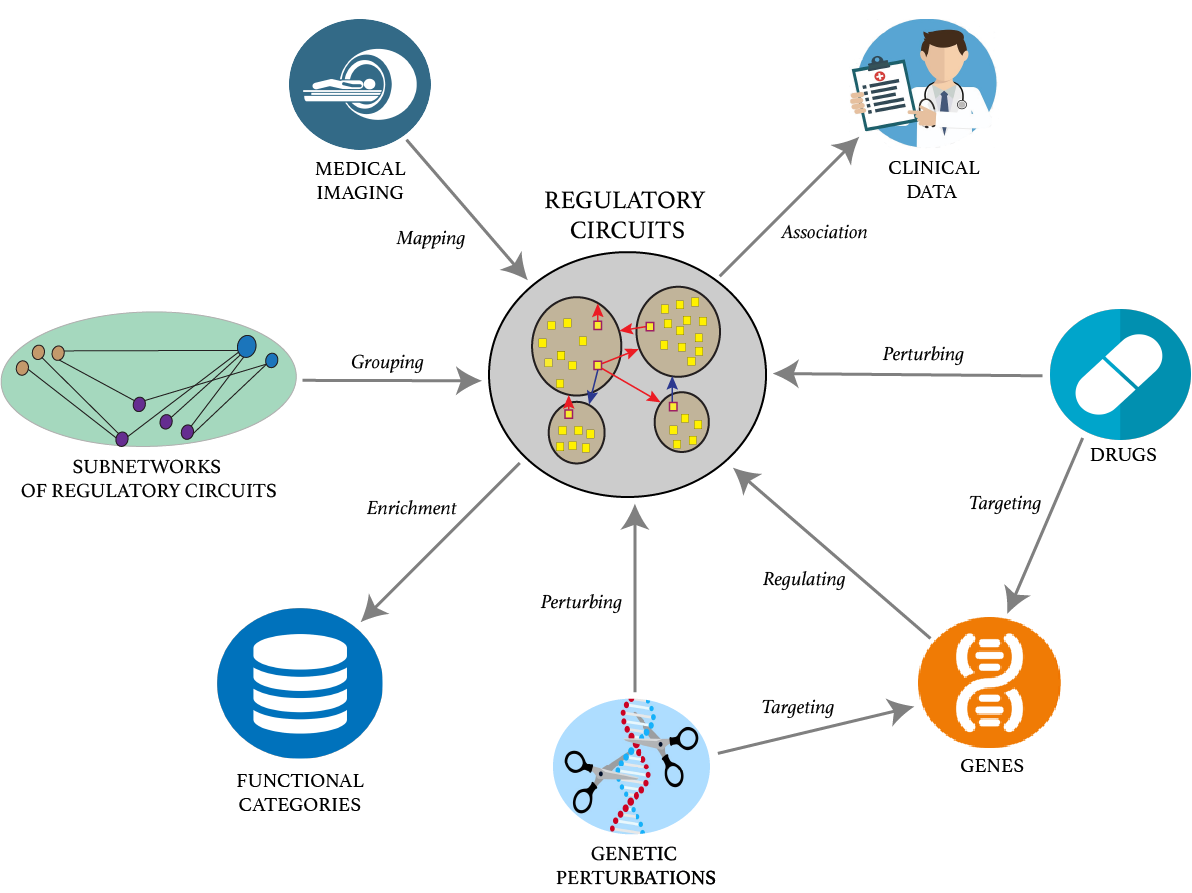
|
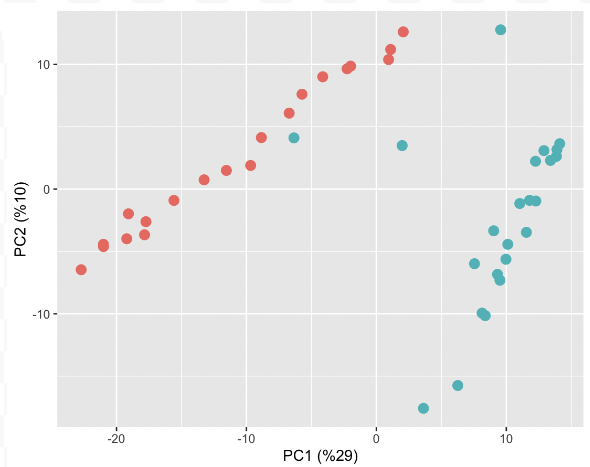
|
| Algorithms and platforms for spatial transcriptomics analysis | Large biological networks for knowledge discovery | Comparative profiling of large omics databases |
| GO | GO | GO |
Statistical Learning/Computing
Computing is an essential part of statistical analysis where building appealing models of data as well as visualizing such data is crucial. A large portion of my work before I moved into computational biology which included building and designing data structures for capturing essential information from the data to either summarize or visualize complex information.
We have built graph models to capture essential information from data for the purpose of statistical learning, and we have also designed software tools to visualize and help analyzing such data (i.e. Dandelion Plot).
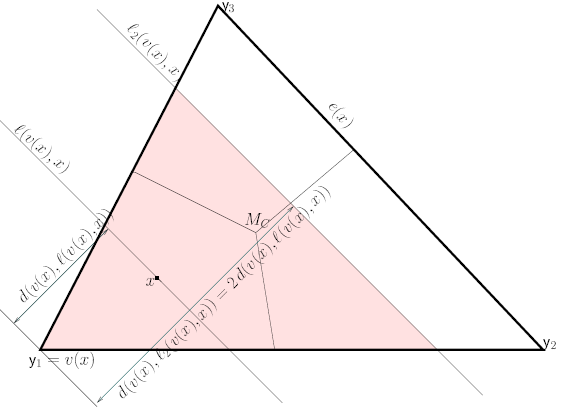
|
|
| Graphical Models to build statistical learning algorithms | Software tools for visualizing factor analysis models |
| GO | GO |